Top 10 Transfer Learning Models
Explore the top 10 transfer learning models that are shaping advancements in machine learning. Learn about VGGNet, ResNet, Inception, MobileNet, EfficientNet, BERT, GPT, XLNet, U-Net, and Transformer. Discover how these models are used to improve performance across various tasks in computer vision and natural language processing. Enhance your understanding of these influential architectures and their applications in optimizing machine learning solutions.
Top 10, Tech | August 22, 2024
Explore the top 10 transfer learning models that are shaping advancements in machine learning. Learn about VGGNet, ResNet, Inception, MobileNet, EfficientNet, BERT, GPT, XLNet, U-Net, and Transformer. Discover how these models are used to improve performance across various tasks in computer vision and natural language processing. Enhance your understanding of these influential architectures and their applications in optimizing machine learning solutions.
The 10 Transfer Learning Models.
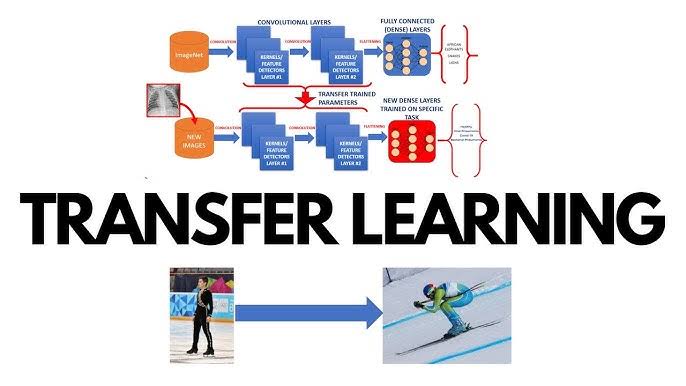
Transfer learning is a technique in machine learning that utilizes knowledge gained from tasks to boost performance on similar tasks. This method proves beneficial in situations where data is limited or when creating complex models from the ground up is computationally expensive. By leveraging models transfer learning can speed up progress and improve accuracy. This article delves into ten notable transfer learning models each recognized for its impact across different fields.
1. VGGNet
VGGNet, developed by the Visual Geometry Group at the University of Oxford, is well known for its straightforward yet powerful design. The structure of the model comprises convolutional layers utilizing 3x3 filters enabling it to grasp intricate details while keeping computational demands in check. VGGNet finds applications, in image classification and is a reliable feature extractor in various transfer learning scenarios.
2. ResNet
ResNet, short for Residual Networks, was created to tackle the issue of gradients in deep neural networks. It incorporates blocks with connections that bypass layers. This architecture enables the training of deeper networks without a drop, in performance. ResNet has demonstrated success across tasks such as image recognition and object detection.
3. Inception (GoogLeNet)
Inception, commonly known as GoogLeNet, utilizes a unique structure that blends various convolutional and pooling techniques simultaneously. This configuration, called an "Inception module," enables the model to grasp diverse characteristics at levels. Inception has proven successful in enhancing precision while minimizing expenses, establishing itself as a favored option for transfer learning in the field of vision.
4. MobileNet
MobileNet is optimized for use in edge devices with capabilities. By employing depthwise separable convolutions it minimizes the models size and computational needs without compromising accuracy. Its design makes it ideal for implementation on devices with limitations. MobileNet finds applications in scenarios that demand performance and quick response times.
5. EfficientNet
EfficientNet is a sophisticated model that optimally adjusts the depth, width and resolution of a network through a scaling approach. By proportionately modifying these factors the model achieves accuracy with fewer parameters than other architectures. EfficientNet has established records in tasks like image classification and object detection showcasing its prowess in transfer learning applications.
6. BERT
The Bidirectional Encoder Representations from Transformers (BERT) stands out as a significant advancement in the field of language processing (NLP). Unlike conventional language models that analyze text in a way BERT takes into account context from directions. This bidirectional method enables BERT to excel in a range of NLP tasks such, as answering questions, sentiment analysis and identifying named entities.
7. GPT (Generative Pre-trained Transformer)
The GPT model, created by OpenAI, is a player in the realm of processing. It employs a transformer architecture and undergoes training on a vast amount of text data. With its ability to generate text that is both coherent and contextually appropriate GPT proves valuable for various applications like completing sentences, translating languages and summarizing information. Its approach to learning has greatly propelled progress in the area of language generation.
8. XLNet
XLNet improves upon BERT by tackling its shortcomings. It uses a training method that involves rearranging sequences to capture context while still maintaining the sequential nature of language models. This approach boosts the models capacity to grasp linguistic nuances and boosts its performance, across various language processing tasks.
9. U-Net
U-Net is a model specifically developed for segmenting medical images in the field of research. It has a design that includes an encoder decoder framework with connections to ensure accurate detection and segmentation of features. U-Net is widely used in the field of imaging providing precise analysis for various types of images like MRI scans and tissue samples.
10. Transformer
The Transformer architecture, presented in the research paper "Attention is All You Need," has brought about a change in the realm of Natural Language Processing (NLP) by removing the reliance on layers. Instead it relies purely on attention mechanisms to handle data sequences. This design has shown success in tasks like translating languages and generating text. Transformer based models such as BERT and GPT have established benchmarks in performance across a range of NLP tasks.
Conclusion
Transfer learning has emerged as a technique for utilizing knowledge and boosting performance in areas. The architectures mentioned here are among the most impactful and commonly used in transfer learning. Whether it's in the realm of vision or natural language processing these models provide effective solutions for tackling intricate challenges with improved efficiency and precision. By grasping and implementing these transfer learning approaches professionals can elevate their machine learning initiatives and foster advancements in their specific domains.